从 0 到 1 构建 RLHF 系统——小红书大模型团队的探索与实践
本文由 简悦 SimpRead 转码, 原文地址 mp.weixin.qq.com
在 QCon 上海 2024 大会上,小红书大模型团队分享了自研 RLHF 系统的设计和优化。本文将介绍,随着 LLM 的发展,超长文本、多模态、PPO(Proximal Policy Optimization)训练本身的复杂度等带来了巨大的技术挑战,AGI 团队通过异构、同构组网架构以及一系列训推一体优化方案,全面超越开源框架,并展示了 RLHF 之后模型的效果提升。
在人工智能技术的快速发展中,多模态大语言模型(MLLM)以其强大的图文理解、创作、知识推理及指令遵循能力,成为了推动数字化转型的重要力量。然而,如何使这些模型的输出更加贴近人类的风格、符合人类的偏好,甚至与人类价值观保持一致,成为了一个亟待解决的问题。为了应对这一挑战,基于人类反馈信号的强化学习方法(RLHF)应运而生,其中,PPO(Proximal Policy Optimization)算法作为 OpenAI 的核心技术,在 RLHF 阶段扮演着关键角色。
小红书大模型团队,在这个技术日新月异的时代,开始了他们自研 MLLM RLHF 训练框架的征程。他们深知,要构建一个高效、准确的 RLHF 训练系统,需要综合考虑算法优化、系统架构、训练调度以及推理引擎等多个方面。
1.1 RL 强化学习原理
在介绍本文工作之前,我们先了解一下 RL 强化学习的原理。
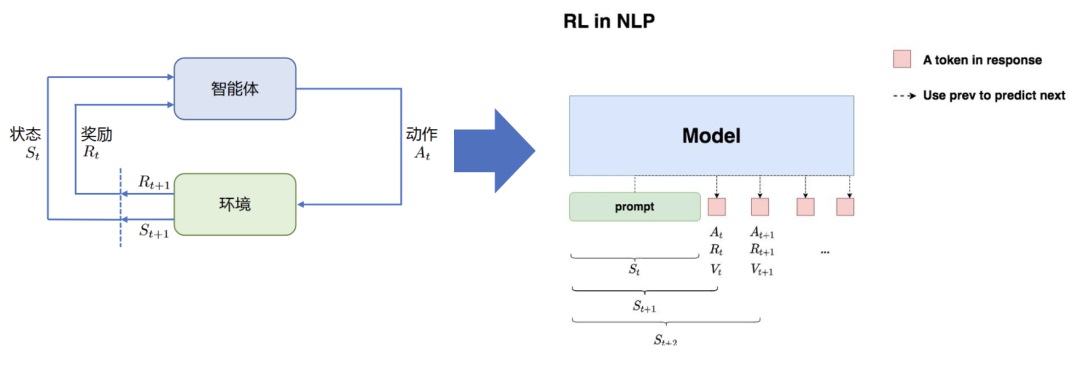
状态 S: 输入 prompt
动作 A: 输出 response
奖励 R: 根据 prompt+response 进行奖励模型打分
给定 prompt,调整 policy,生成符合人类喜好(RM 偏序信号)的 response
RL 强化学习用在游戏、自动驾驶等场景较多,简单解释就是智能体在特定环境下进行不同策略的 action、并给出反馈进行状态更新的过程,可以理解为自闭环;对应到 NLP 下,大语言模型就是智能体,输入的提示词 prompt 就对应状态 S,输出下一个 token 就是动作 A,对 prompt+res 进行打分就是奖励 R,整体目标就是给定 prompt,调整 policy 策略模型,生成符合人类喜好的 response,这个喜好就是 RM(Reward-model) 的偏序信号。
1.2 RLHF-PPO 算法
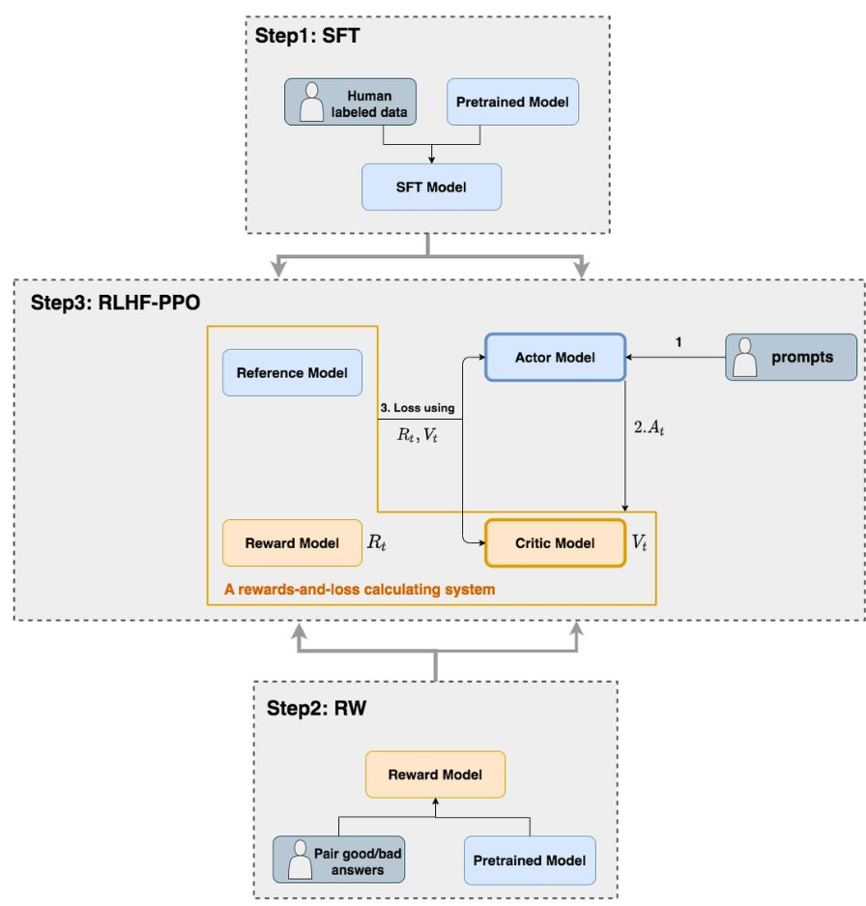
RLHF 的流程主要是 RM+RL 两个阶段,sft 是 RL 的前置阶段,一般作为 RM/RL 的初始化模型。
第一阶段是 RM,偏好训练一个 reward-model 打分模型,这里的数据是有偏的,目的就是模拟人类视角去评价一条数据的质量。
第二阶段是 RL,LLMs 根据训练集的指令生成自己的偏好回复,并根据 RM 的实时打分,进行策略优化,不断生成接近人类的偏好输出。
RL 算法一般有 on-policy、off-policy 两类,OpenAI 在 RLHF 阶段采用的有效算法是 PPO,PPO 是一种 on-policy 算法,需要在线生成样本,被普遍认为是效果较好的一种 RL 算法,所以我们 RL 训练也是基于 PPO 进行设计和优化的;
RL 训练 - PPO**(Proximal Policy Optimization 策略梯度算法):
- Actor Model: 演员模型,训练的目标语言模型
- Critic Model: 评论家模型,预估总收益
- Reward Model: 奖励模型,计算即时收益
- Reference Model: 参考模型,“约束”,防止模型训歪
PPO 是一种经典的策略梯度算法,具体算法涉及到 actor/critic/reward/reference 4 个模型的协同训练和推理,设计和实现一套高效、准确的 RLHF 训练系统,是关键挑战之一。
PPO 训练流程
下面介绍一下 PPO 的训练流程,PPO 是一个训推混合的训练流程,如下图所示,可以分为两个步骤,一个是 make-experience,一个是 training。
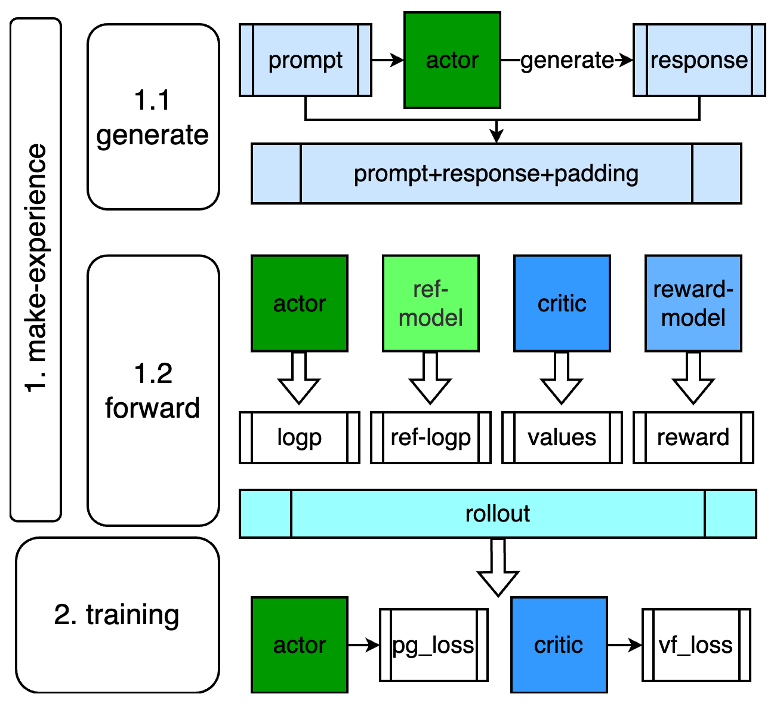
第一阶段经验采样,有时候也叫做 rollout,就是滑跑的意思,在 RL 中可以理解为一次实验,也就是 actor 模型在当前环境下进行策略动作的过程,具体实现上就是 actor 模型根据 prompt 数据集进行 generate 生成 response,然后根据 prompt+response 进行 forward 计算,得到 logp/values/reward 等元素,这里涉及到 actor、ref/critic/reward 4 个模型的推理过程;
第二阶段就是训练流程,涉及到 actor 和 critic 两个模型,从计算 loss 来看,算法上是相互独立的,本质上是两个模型独立训练;
工程实现上的痛点也比较明显:涉及到多阶段的 dataloader(prompt 和 rollout、train),actor 模型的 generate 自回归过程,以及 4 个不同的模型推理,2 个不同的模型训练。
当然整体来看 make-experience 阶段部分就给我们提供了一定的优化空间。
2.1 整体架构
架构选型
训练:
apex/nemo/megatron-lm/pytorch-lighting/accelerate/ray
=> Megatron-core+ray
推理:
vLLM 推理引擎(logp 用 megatron)
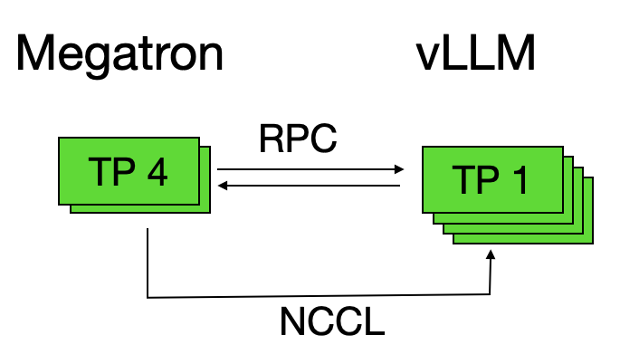
下面介绍我们的整体系统架构,框架选型上我们吸取了开源比如 trlx/openrlhf 的痛点,比如 apex/nemo/megatron 等混合框架的组合缝合怪方式,这会给代码维护和更新增加成本,因此我们降维到 megatron-core 作训练,ray 做调度的方式降低维护成本;推理服务我们使用 vllm 推理引擎,当然需要注意的是,vllm 也可以输出训练所需要的 logp 数据,但还是要和训练保持一致,走 megatron 框架,否则会引入框架之间的 diff,成为训练的 bias,引入风险;
该图为我们的整体架构,上面是 make-experience 的第一步骤,dataloader 迭代器返回 prompt 之后,通过 vllm 的 generate 输出 response,prompt 和 response 组合之后成为新的 forward 数据集;左下方是第二步骤,也就是进行 4 个模型的 forward,生成最终的 ppo-elements 或者简称 rollout,构造最终的 train 数据集;右方为 PPO 训练,actor 训练之后会进行参数同步,这里会涉及到 medusa-sft 的协同训练流程,最终同步给 vLLM 进行新一轮的 generate 等。
2.2 异构组网架构
从 0 到 1 优化设计
1.Forward-Offload: 纯串行实现,分时复用 model:4->2
2.Training-Seperated: actor/critic 独立集群异步训练(并行化)
启动流程: actor 集群上进行 torchrun 启动主进程训练,并自动以 mock 方式拉起 critic 所在集群——remote-func
下面介绍异构组网架构,RL 的 workload 涉及到 4 个模型,如果全都串行实例化每个 model,成本较高,但根据前述分析来看模型结构相同,所以我们设计了异构组网架构,能够大幅提升性能;
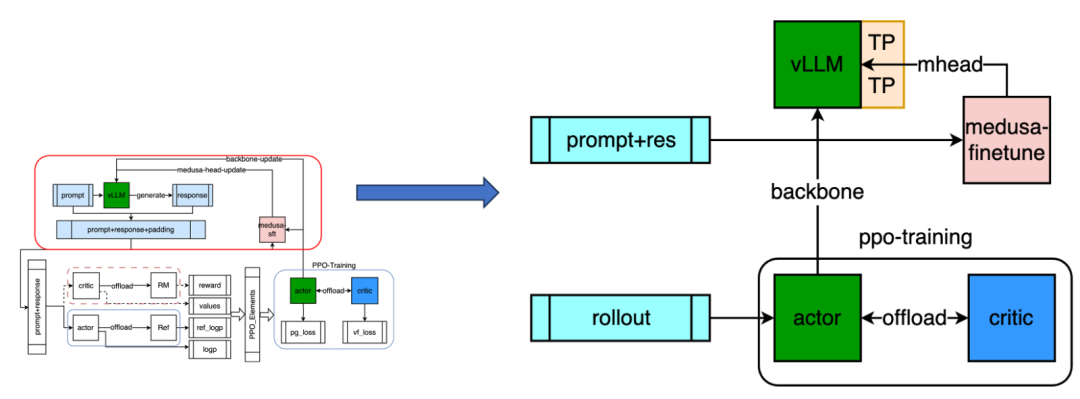
如上图所示:
Forward 阶段涉及到的 4 个模型通过 offload 的方式可以进行串行实现(actor->offload->ref,critic->offload->RM),能够分时复用集群,整体 model Memory 从 4 降到 2,以 llama3 70B 为例,需要 8 机 64 卡跑一个模型,那么原始的纯并行方式需要 4 倍,也就是 32 机 256 卡跑一组实验,通过 offload 的方式可以降低到 16 机 128 卡,降低模型所需要的 GPU 集群规模;
Training 阶段实现 seperated 分离的方式,一方面 actor/critic 模型需要独立参数,另一方面通过独立集群部署可以实现异步训练,所以通过异步的方式可以保证吞吐最大化,这一版本架构已经具备一定可用性,相比开源框架比如 trlx/openrlhf 提升 50% 以上;
启动方式:异步的启动方式是复用 torchrun 拉起主任务,我们实现 mock-run 的方式,继承同等规模的 actor 集群信息,能够在远端自动拉起 critic 所在的集群。
2.3 同构组网架构
新的瓶颈出现,见招拆招
异构组网的痛点:
-
数据量,seq,模型参数量,集群规模压力加大(以 llama3 70B 为例,SFT 模型本身需要 4 机 32 卡,32k 长文下 CP2=>8 机 64 卡
-
rollout 同步:序列长度、多模数据量增加,同步的通信耗时增加
AC 同构组网架构:AC 复用集群,main-model 2->1 ——tride-off
forward 阶段:offload param 进行模型切换 training 阶段:offload 中间状态(param/grad/ddp-bucket/opt)
接下来介绍同构组网架构,当数据量、模型规模等都增大的情况下,集群规模压力也大幅增大,我们以 llama3 70B 为例,SFT 模型本身需要 4 机 32 卡,32k 长文下需要开启 CP2,也就是需要 8 机 64 卡,即便是 DP1,原始异构组网也需要 16 机 128 卡,这个对于资源的压力是较大的;另外异构组网因为需要 master-worker 架构的拉远实现,需要同步 rollout 的 buffer 数据,当多模数据增加了图片等数据后,会大幅增加 rollout 同步所需要的开销;
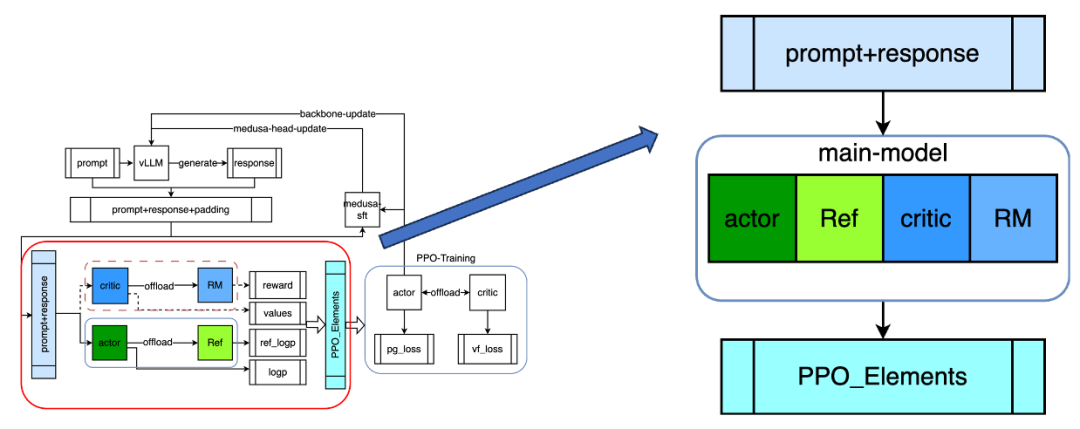
所以我们进一步实现了异步组网架构,前面讲到 forward 阶段的 2 个模型的同构,训练阶段是异步的,但其实 actor 和 critc 部分也是类似,可以通过 offload 完成进一步的 scale,集群规模降低到单个 sft 所需的训练规模,具体实现上,forward 阶段只需要 offload-param 即可完成模型切换,training 阶段,需要切换较多的状态,包括 param、grad/ddp-bucket/opt-state 等所有显存开销, 虽然会增加上下文切换的开销,但相比训练本身的时间相对较小;
这里列举了方案对比,AC 异构训练,吞吐最高,但所需集群规模较大,AC 同构组网通过完全复用集群的方式,集群资源最小,且最大化性能。

3.1 训练性能优化
数据加载: prefetch,双 dataloader(ptx-loss)
并行优化: TP/PP/CP/SP
显存优化: recompute,大模型 + 长文本
Dynamic-batch: 推理、训练不同 batchsize
负载均衡: prompt 请求 Round-Robin 到 vllm-engines
vllm 优化: 调整切分,虽降低 running-batch,能提高并发
首先是一些常规的训练性能优化方法,数据加载部分采用 prefetch,比如 ptx-loss 的时候存在双 dataloader,这里就需要降低 num-workers 数,防止 CPU-OOM;并行策略上,使用 megatron 的 TP/PP/CP/SP 并行方法;在长文和大模型下采用 recompute 方式进行显存优化;dynamic-batch 部分的训练和推理用不同的 batchsize,因为推理不需要梯度优化器等显存占用,所以 bs 可以更大;vllm 部分优化采用的是 round-robin 的方式把 prompt 请求分发给多个 vllm-engines 进行负载均衡,并且推理服务的 TP 并行切分可以更细,比如 TP4 到 TP1,虽然降低了 running-batch,但是能够增大 vllm 并发数,把整体的吞吐进一步提升。
3.2 Pipeline 优化
问题:
actor 进行采样阶段,训练无需进行,存在较大的空窗
思路:
• 训推集群混布,增大 serving 并发,降低 generate 耗时
• 类比 pp 并行,把 generate 和 forward 阶段进行流水线并行
整体调度优化:
• 全量 offload:
•vLLM:kvcache 销毁,param-offload
•Forward:actor/critic 的 param/buffer-offload
• 资源最大化:vLLM 资源合并到 train
• 流水线优化:Make-experience 阶段最大化
进一步分析发现,actor 进行采样阶段,训练无需进行,存在资源浪费,即便是通过训推资源的混合切换,也会存在较大的空窗;因此我们设计了 pipeline 的流水线。主要思路是首先通过训推集群混布,增大 serving 并发,降低 generate 耗时,我们实现了 vllm 和 megatron 的全量 offload;vllm 部分支持 kvcache 的销毁,param-offload,forward 部分涉及到 actor/critic 的 param 以及其他 buffer 的 offload 切换,最终可以把 vllm 资源合并到 train 内部,实现资源最大化;并且通过类比 PP 并行,把 generate 和 forward 阶段进行流水线并行, 通过细粒度的 mini-batch 切分 workload,大幅降低 make-experience 阶段的整体耗时。
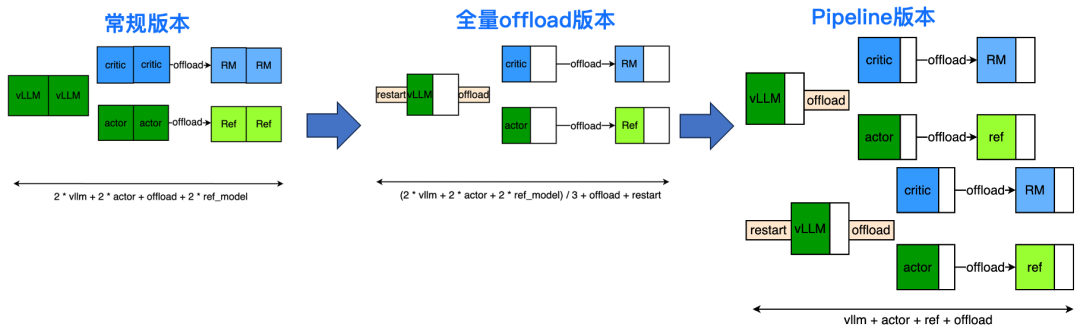
我们整体对比一下不同的实现方式:
-
常规版本:每个节点独立运行各自的任务,推理在推理集群上部署,ac 的训练和推理也在各自的集群上部署,但是推理服务和训练性能差异较大,存在一定优化空间;
-
全量 offload:相当于 vllm/actor/critic 分别进行全集群的资源利用,这种方法实现简单,可以充分提高 generate 的并发能力,roi 较高;但是也引入了明显的 offload/restart 等空隙;
-
Pipeline 版本:通过流水线机制可以 overlap 掉数据落盘、restart/offload,以及一部分 forward 等开销,在多模等复杂场景下,可以进一步 overlap vit 等上下文开销,在开源模型上训练时性能最优。
3.3 PPO 细节处理
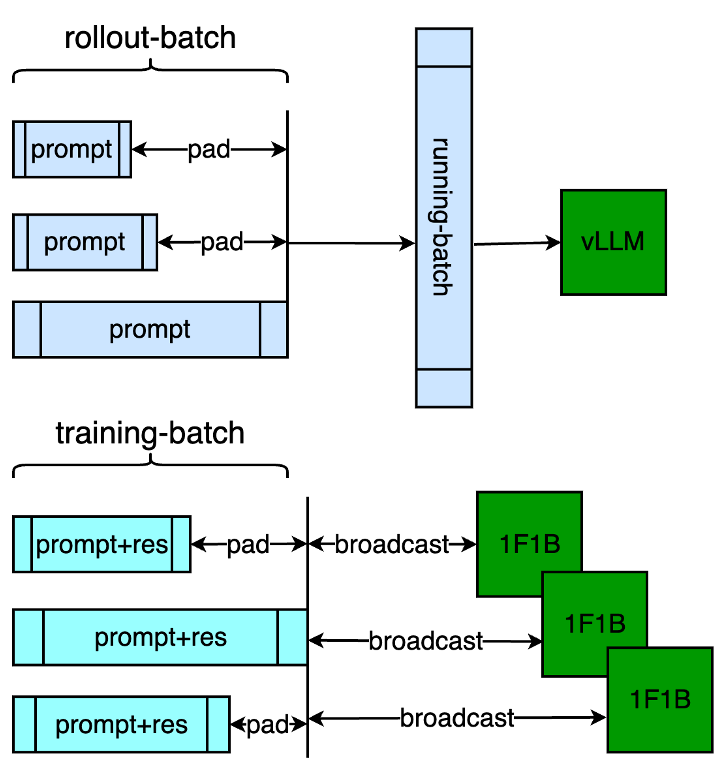
针对 PPO 我们做了一些细节处理:
padding-free 优化,对 generate/forward/train 三阶段进行 padding 的去除,vllm 通过 running-batch 进行排队,forward 和 train 通过 megatron 的 1F1B 之前进行 broadcast 即可保证 micro-batch 内部的正常运算,整体提升 10%;
Vllm 和训练部分的参数同步上,通过提前和 ray-vllm 组建 ncclGroup 的方式完成,相比走文件系统的 reload 方式进一步提升几十秒;
CP 并行部分与传统 sft 不同,需要进行 logp 以及 values/reward 的重排,比如 logp 部分,规避对 logits 进行 gather 的方式,先统一得到 total 的 logp,这样可以把通信量从 bsh 降低到 bs。
3.4 多模 MLLM 优化
MLLM (Multimodal Large Language Model)
痛点:
vlm 部分需要图像处理,图文混合,负载不均衡
特点:
- 视觉部分计算量大,但参数量较小
2.PPO 场景下图像处理存在冗余
优化:
- 组网优化:llm 的 tp/pp/cp 用作视觉部分的 dp
- 多路复用:vllm/actor/critic 复用相同的 img_feature
- Prefetch:frozen visual-model,通过 prefetch 的机制,融合进 make-experience 做 Pipeline 的 overlap
在大规模的场景下,图文混合场景增大的复杂度,也带来了新的瓶颈,因此需要进行特定的性能优化:
我们观察到视觉部分计算量大,llm 部分模型权重大。针对这个现象,可以对视觉部分和 llm 使用不同的并行策略:视觉部分只有 dp; llm 部分有 mp + pp + cp。把 llm 部分的 pp、mp、cp 用作视觉部分的 dp;
MLLM 针对特定的训练任务进行优化,目前 sft/RL 阶段均采用 frozenvisual-model 的方式进行,只是微调 adapter 部分,所以可以进行多路服用,vllm/actor/critic 三者复用相同的 img_feature;
并且通过 prefetch 的机制,类似把 vit 视觉部分的整个实现放到 dataloader 内部,通过与 make-experience 阶段结合 Pipeline 做 overlap,能进一步降低预处理的耗时。
3.5 训推一致性
确定性训练和推理
问题:
- RM 的精度要求——RM-serving,acc 掉点
- 推理评估的精度要求
原因:
rm 的 vhead 是一个 linear,y=xA^T+b
本质上是一个矩阵乘,[1,hidden] * [hidden,1]
如果 logits 存在框架等 diff,则会放大误差:初始 diff ~= 0.001,矩阵乘之后达到 0.3
训推一致性是对工程架构的一个考验,比如训练之后的模型走推理框架评估可能会存在打分差异,特别的,算法上严格要求 RM(Reward-Model)的精度一致,最早通过 RM-serving 进行 accuracy 统计发现掉点,经过排查发现是因为框架的 diff,逐位误差在千分位,但是 RM 的 vhead 是一个 linear,本质上是一个矩阵乘,相当于扩大了 hidden 平方倍,精度无法容忍;
我们的解决方法如下:
-
RM+RL 的训练均使用相同的训练框架;
-
RL 场景下要把 RM-serving 走 api 的方式转为本地 offload 去做 forward,这样能够保证训推完全一致,且没有额外的 serving 占用和通信开销;
-
训推一致性,训练和推理采样 mcore 的计算 workload,保证评测任务上训推 tokenwise 一致,如下图所示,多个评测 case 上完全相同;这里也会涉及到一些技术实现,比如通过 allgather+local-reduce 实现替换 allreduce,cublas 的调优选项对齐等细节处理。
3.6 Medusa 提升采样效率
投机采样无损优化
问题:
•actor 进行 generate 采样耗时较为明显
• 传统量化等方式有一定的精度损失,要求无损优化
推理优化:
• 投机采样能无损优化自回归性能
• 计算换空间,FLOPS -> VRAM 带宽
•Medusa:多个 head,frozen 主干
•Running-batch:吞吐量最大化
Rollout 阶段的 generate 耗时始终是一个大头,所以我们结合推理部分进一步优化,但传统量化等方式有一定的精度损失,为了稳定 PPO 训练,也要要求无损优化。
投机采样是一种无损优化,通过多个头的预测来降低 decode 次数,因为自回归部分主要为 Memory-bound,进行计算并行优化,也是一种计算换空间的方式。这里我们采用的是 medusa 算法,由主干网络加上多个 medusa-head 组成,每个 MedusaHead 是和 LM-Head 一样结构,分别对应到预测每个头的 topk 的 token,并且 RL 场景下需要组 batch 关注的是吞吐,不需要考虑延迟,所以 running-batch 尽可能大才能提高整体吞吐量;
伴生训练设计
问题:
Backbone vs mhead 的匹配,接收率下降
伴生训练:
- 精度无损:backbone 实时更新, mhead update
- 训练 overlap:mhead 的更新可以延后于主干
- 少量微调:数据量 rollout-batch-size
性能说明:
由于 RL 训练阶段均为组 batch,所以提升效果有折损,generate 部分性能提升 50%+
但 RL 场景下存在一个问题,actor 模型在不断更新,medusa 的接收率(猜测准确越高,降低 decode 次数越多,越能提升推理效率)会下降,降低加速效果,就得不偿失了,所以我们提出伴生训练的方式,目的是为了更新 mhead;
在精度无损的要求下,backbone 部分需要实时更新,而 mhead 的更新可以延后于主干(只是接收率下降),且 medusa 的训练在 RL 的上游 sft 阶段已经完成训练,进入到 RL 之后再次进行微调,此时的训练数据已经变为 rollout-batch-size,所以只需要按照 rollout-bs 的大小进行少量微调,所以只需要单台机器即可训练 medusa,并且伴生训练可以和训练阶段 overlap,参数更新的耗时也是无损的;
性能收益来看,medusa 会有一定的计算开销,batchsize 增大会降低性能收益,但即便是 running-batch 打满的情况下,仍然有 50% 性能收益。
4.1 通用能力提升
我们用开源模型 RL 后可以获得通用能力提升,这里列了两个 case:

第一个是指令跟随,比如 prompt 为午餐吃什么,原始 sft 也是正常语义,但回答的是早餐,RL 之后可以正确回答午餐内容;

第二个 case 为丰富性,比如 prompt 提问是否能够解决内部冲突问题,原始 sft 也能正确回答,但是回答太过简短,只有一个是的,相比之下 RL 的回答还有额外的解释,当然丰富性通过 response_len 也可以看出 RL 之后的长度更长;
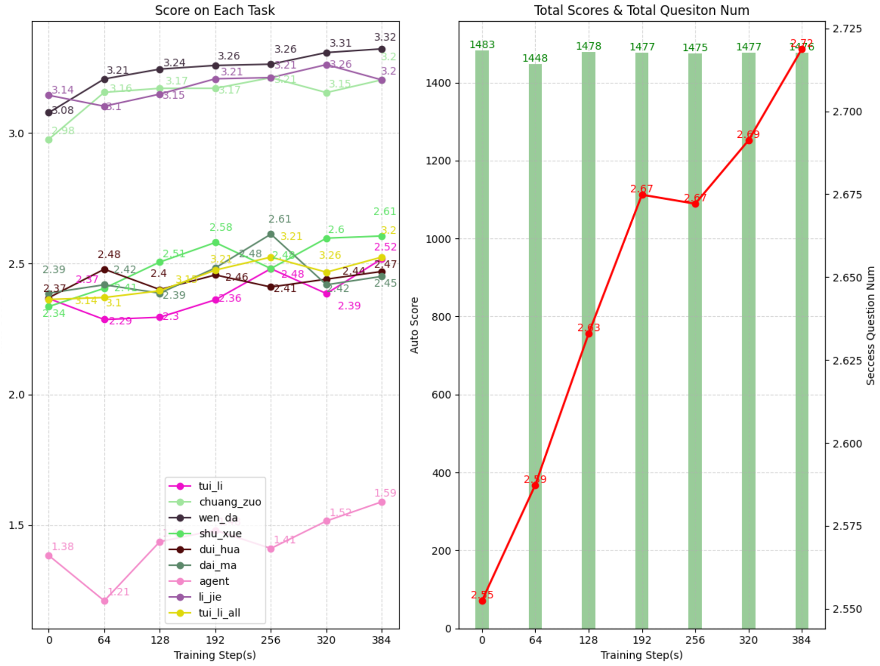
整体上,基于开源模型做 RL 后,相比基线 sft GSB 提升 5-20%,不同模型有一定差异,模型越强增益越小;右图所示为某开源模型在 RL 之后的各项任务打分,推理、数学提升较多,综合自动化评分有 6% 的提升,表明 RL 能够提升通用能力。
4.2 PRM 效果提升

我们也开发了 PRM 也就是基于过程的训练模式,基于 PRM 的过程奖励,可以增强可解释性,比如这个 case 是推理小赵换到小吴位置需要几个步骤,标准答案是需要换 3 次,PRM 不仅推理结果正确,而且中间推理过程也能对不合理的部分进行惩罚,比如中间错误的说辞以及冗余的推断逻辑。
通过 PRM 能够让激励更准确,比如在相同的输出情况下,ORM 和 PRM 的分差 reward-gap 会加大,更有区分度,更细力度的打分也能指导推理的过程,最终提升模型的上限 5%。
4.3 调参经验
• 可视化逐样本 / token 进行细粒度分析
•Advantage-batch 对于小 DP 场景较为有用,防止走的偏
•Critic 从 RM 进行参数加载,复用训练集群进行 reward 的 batch-forward 提高推理效率
•LR:基于 sft 进行设置,actor<critic,否则容易发散 < span="">
•Critic 先学习,actor 先 frozen,更准确的学习
•reward hacking 奖励攻击:奖励后期的收敛性 vs 评测结果的差异。
PPO 调参需要依赖一个鲁棒的系统,一些可视化的分析是有必要的,除了常用的 tensorboard 看 loss/reward 训练指标之外,还可以通过上图所示的具体 rollout 信息,进行逐样本更细粒度的分析;
调参方面有一些细节,比如 advantage 平滑的时候在整个 rollout-batch 进行,尽可能增大激励的稳定性,防止走偏;critic 从 RM 进行参数加载,走本地 offload 可以保证精度的同时提高 Reward 的 forward 效率;lr 一般基于 sft 进行设置,actor 要小于 critic,否则容易发散;尽可能让 critic 先学习,frozen 住 actor,让 critic 具备一定的评判能力,保证走的更准确;还有 reward-hacking 问题,训练指标可能持续增加,但评测集已经开始下降一般就是 reward-hacking 了,需要进行 rm 的迭代训练。
4.4 未来规划
未来计划主要围绕两个主题,一个是进一步的性能优化,一个是算法探索:
性能优化方面,MATRIX(MultimodalAI Training and Inference eXecutor)是 AGI 团队进行多模态大语言模型大规模分布式预训练、可监督微调、人类偏好对齐训练和在线推理的统一框架;
比如结合内部自研的推理引擎进一步压缩 generate 的耗时,不同 seq 的负载均衡,目前 Pipeline 优化主要针对 rollout 阶段,后续也可以结合训练做深度流水调度。
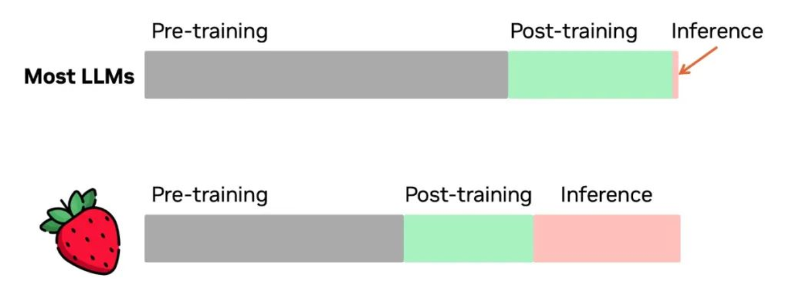
AGI 的算法上,其实预训练的 scaling 已经吃的差不多了,通过 post-train 还有一定空间,单一的 sft 无法满足,通过 RL 可以进一步提升,甚至是 infer 阶段的 scaling,比如现在 OpenAI 的 O1 实现,提升推理性能,虽没有公开细节,但已经有一些揣测,比如按照 RL 的迭代流程,sft 是无法推断正确,但通过 PRM 的 RL 训练后,模型有了更强的推理能力,也是对 RL 的 scaling-law 的探索。
作者:
唯世:小红书大模型分布式训练工程师,负责多模态分布式训练框架的研发和优化。
云开:小红书大模型分布式训练工程师,负责多模态分布式训练框架的研发和优化。
霍金:小红书大模型分布式训练工程师,负责多模态分布式训练框架的研发和优化。
杜弼:小红书大模型分布式训练工程师,负责多模态分布式训练框架的研发和优化。